前世今生
Stream 是 Java 8 的一个特性,支持声明式处理数据,目的是为了解放程序员操作集合(Collection接口)时的生产力,其中的 Lambda 表达式——极大的提高了编程效率和程序可读性。
直观理解
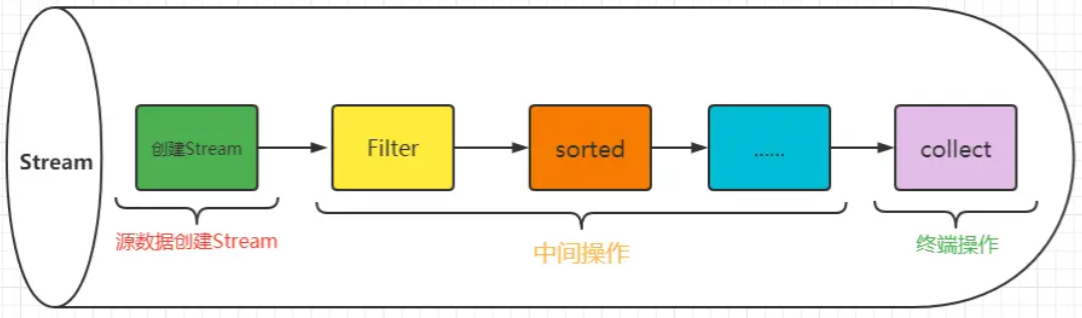
流(Stream)就像是一条河流或者管道,数据按序流过,中间经过某些处理(筛选、排序、聚合等),最终输出一个流或者一个集合。
几个特性
Stream不存储数据,而是按照特定规则顺序处理数据,一般会输出结果Stream不改变数据源,通常情况下产生新的集合或值Stream具有延迟执行机制,只有在调用终端操作时,中间操作才会执行
两种操作
中间操作
将一个流转换为另外一个流
中间操作符包含8种(排除了parallel, sequential,这两个操作并不涉及到对数据流的加工操作):
map操作
用于将流中的元素转换为其他形式或类型。它通过一个 Function 接口的实现,将流中的每个元素应用一个函数,并将结果收集到一个新的流中。map方法广泛应用于以下场景:
- 数据转换:将流中的元素转换为另一种形式。
- 数据处理:对流中的元素应用特定的处理逻辑。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);// 创建一个列表 List<Integer> list = Arrays.asList(1, 2, 3); System.out.println(list); // 使用map操作映射 List<Double> mappedList = list.stream().map(x -> Math.pow(x, 2)).collect(Collectors.toList()); // 输出结果 System.out.println(mappedList);//[1.0, 4.0, 9.0]
flatmap(flatmapToInt,flatmapToLong,flatmapToDouble)拍平操作比如把int[]{2,3,4}拍平 变成 2,3,4 也就是从原来的一个数据变成了3个数据,这里默认提供了拍平成int,long,double的操作符。<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);// 创建一个包含多个整数列表的列表 List<List<Integer>> listOfLists = Arrays.asList( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9) ); // 使用flatMap将多个列表转换为单个列表 List<Integer> flatList = listOfLists.stream() .flatMap(List::stream) .collect(Collectors.toList()); // 输出扁平化后的列表 System.out.println(flatList);//[1, 2, 3, 4, 5, 6, 7, 8, 9]limit限流操作,比如数据流中有3个 我只要前2个// 创建一个列表 List<Integer> list = Arrays.asList(1, 2, 3); System.out.println(list); // 使用LIMIT操作 List<Integer> mappedList = list.stream().limit(2).collect(Collectors.toList()); // 输出结果 System.out.println(mappedList);//[1,2]distinct去重操作,对重复元素去重,底层使用了equals方法。// 创建一个列表 List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); System.out.println(list); // 使用 distinct 操作 List<Integer> mappedList = list.stream().distinct().collect(Collectors.toList()); // 输出结果 System.out.println(mappedList);//[1, 2, 3, 4]filter过滤操作,只过滤出符合断言条件的数据。Stream<T> filter(Predicate<? super T> predicate);// 创建一个列表 List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); System.out.println(list); // 使用 filter 操作 List<Integer> mappedList = list.stream().filter(x -> (x & 1) == 1).collect(Collectors.toList()); // 输出结果 System.out.println(mappedList);//[1, 3, 3]peek操作,是一个中间操作,函数签名如下:Stream<T> peek(Consumer<? super T> action)参数:将
Consumer作为操作方法传递。
返回:该方法返回一个新的流。peek方法主要用于调试,以便在元素流过管道中的某个点时查看它们。peek方法是中间方法,因此在调用终端方法之前它不会执行。Stream.of(10, 20, 30).peek(e -> System.out.println(e));不会有输出。
现在在上面的代码中使用一个终端方法Stream.of(10, 20, 30).peek(e -> System.out.println(e)) .collect(Collectors.toList()); 10 20 30peek在调试中的作用:Stream.of(10, 11, 12, 13) .filter(n -> n % 2 == 0) .peek(e -> System.out.println("Debug filtered value: " + e)) .map(n -> n * 10) .peek(e -> System.out.println("Debug mapped value: " + e)) .collect(Collectors.toList()); Debug filtered value: 10 Debug mapped value: 100 Debug filtered value: 12 Debug mapped value: 120skip跳过操作,跳过前n个元素。Stream<T> skip(long n);List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); List<Integer> collect = list.stream().skip(3).collect(Collectors.toList()); System.out.println(collect);//[2,4,3]sorted(unordered)排序操作,对元素排序,前提是实现Comparable接口,当然也可以自定义比较器。List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); List<Integer> collect = list.stream().sorted().collect(Collectors.toList()); System.out.println(collect);//[1, 2, 2, 3, 3, 4]
结束操作
AKA terminal operation(终端/终止操作)
数据经过中间加工操作,最后遇到终止操作;终止操作符就是用来对数据进行收集或者消费的,数据到了终止操作这里就不会向下流动了,终止操作符只能使用一次。只有遇到终止操作时,中间操作才会真正执行。
collect:收集操作,将所有数据收集起来,这个操作非常重要,官方提供的Collectors提供了非常多收集器,可以说Stream的核心在于Collectors。List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); List<Integer> collect = list.stream().sorted().collect(Collectors.toList()); System.out.println(collect);//[1, 2, 2, 3, 3, 4]count:统计操作,统计最终的数据个数。List<Integer> list = Arrays.asList(1, 2, 3, 2, 4, 3); long count = list.stream().skip(3).count(); System.out.println(count);//3findFirst、findAny:查找操作,查找第一个、查找任何一个,返回的类型为Optional。List<Integer> list = Arrays.asList(1, 3, 2, 4, 5, 2); Optional<Integer> first = list.stream().findFirst(); Integer i = first.get(); System.out.println(i);//1noneMatch、allMatch、anyMatch:匹配操作,数据流中是否存在符合条件的元素,返回值为bool值。List<Integer> list = Arrays.asList(1, 3, 2, 4, 3, 2); boolean noneMatch1 = list.stream().noneMatch(x -> x > 4); boolean noneMatch2 = list.stream().noneMatch(x -> x > 3); boolean noneMatch3 = list.stream().anyMatch(x -> x > 3); boolean noneMatch4 = list.stream().allMatch(x -> x > 3); System.out.println(noneMatch1);//true System.out.println(noneMatch2);//false System.out.println(noneMatch3);//true System.out.println(noneMatch4);//falsemin、max:最值操作,需要自定义比较器,返回数据流中最大最小的值。List<Integer> list = Arrays.asList(1, 3, 2, 4, 3, 2); Optional<Integer> max = list.stream().max(Integer::compareTo); Optional<Integer> min = list.stream().min(Integer::compareTo); System.out.println(max.get());//4 System.out.println(min.get());//1reduce:规约操作,将整个数据流的值规约为一个值,count、min、max底层就是使用reduce。
该操作有3个函数签名,分别为:1. Optional<T> reduce(BinaryOperator<T> accumulator); 2. T reduce(T identity, BinaryOperator<T> accumulator); 3. <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);Identity: 定义一个元素代表是归并操作的初始值,如果Stream是空的,也是Stream的默认结果Accumulator: 定义一个带两个参数的函数,第一个参数是上个归并函数的返回值,第二个是Stream中下一个元素。Combiner: 调用一个函数来组合归并操作的结果,当归并是并行执行或者当累加器的函数和累加器的实现类型不匹配时才会调用此函数。 下面的代码无法通过编译
上代码无法编译的原因是,流中包含的是User 对象,但是累加函数的参数分别是数字和user 对象,而累加器的实现是求和,所以编译器无法推断参数 user 的类型。可以把代码改为如下可以通过编译List<User> users = Arrays.asList(new User("John", 30), new User("Julie", 35)); int computedAges = users.stream().reduce(0, (partialAgeResult, user) -> partialAgeResult + user.getAge());int result = users.stream() .reduce(0, (partialAgeResult, user) -> partialAgeResult + user.getAge(), Integer::sum); assertThat(result).isEqualTo(65);forEach、forEachOrdered:遍历操作,这里就是对最终的数据进行消费了。toArray:数组操作,将数据流的元素转换成数组。
定义流
定义一个流对象(Stream)有以下几种方式:
方法一:通过java.util.Collection.stream()方法
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false); public class Main {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
Stream<Integer> stream = list.stream();
stream.forEach(System.out::println);
}1
2
3
4
5
6方法二:2、使用java.util.Arrays.stream(T[] array)方法用数组创建流
int[] array={1,3,5,6,8};
IntStream stream2 = Arrays.stream(array);方法三:使用Stream的静态方法:of()、iterate()、generate()
Stream<Integer> stream3 = Stream.of(1, 2, 3, 4, 5, 6);
Stream<Integer> stream4 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream4.forEach(System.out::println);//0 3 6 9
Stream<Double> stream5 = Stream.generate(new Random()::nextGaussian).limit(3);
stream5.forEach(System.out::println);
//-0.7725940408383488
//-1.7799169104768222
//2.443342791303781顺序流和并行流
stream是顺序流,由主线程按顺序对流执行操作;parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。
例如筛选集合中的奇数,两者的处理不同之处: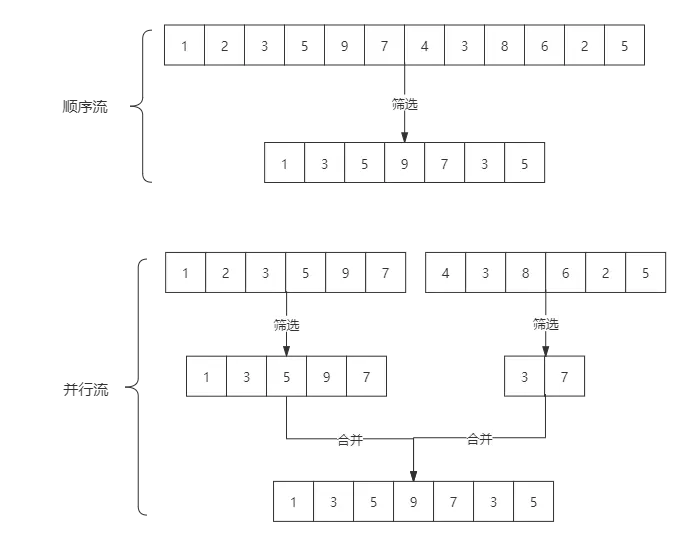
下面给出一个求前一千万个整数当中所有的奇数的两种流式操作对比,可以看到处理时间上天壤之别。
List<Integer> list = IntStream.rangeClosed(1, 10000000).boxed().collect(Collectors.toList());
Stream<Integer> stream6 = list.stream();
Stream<Integer> stream7 = list.parallelStream();
StopWatch stopWatch = StopWatch.createStarted();
List<Integer> collect1 = stream6.filter(x -> (x & 1) == 1).collect(Collectors.toList());
stopWatch.stop();
System.out.printf("串行流耗时%s ms",stopWatch.getTime());
System.out.println();
stopWatch.reset();
stopWatch.start();
List<Integer> collect2 = stream7.filter(x -> (x & 1) == 1).collect(Collectors.toList());
stopWatch.stop();
System.out.printf("并行流耗时%s ms",stopWatch.getTime());
//顺序流耗时2215 ms
//并行流耗时97 ms


